
In “The Intelligence Inflection”, I argued we’re drinking from a firehose through a coffee stirrer. Models accelerate while we plod along at 40 words per minute, re-explaining ourselves every session. The drag isn’t the silicon - it’s us. Our limited bandwidth, our context resets, our fatigue.
This piece is the hinge between philosophical concepts and the deep technical series that follows. It’s about why local, persistent-memory agents matter, and the architecture I actually built to make that claim real.
A note on this series: This is as much a technical deep dive as an authentic learning journey. I don’t claim anything here is novel, as the subtitle of the code section says, “I reinvent the wheel to learn why it’s round.” The full codebase on GitHub will be open-sourced once complete. This work is done entirely on personal time and has no relationship to my day job.
For readers new to generative AI: Technical terms are underlined with quick explanations on hover/tap.
The Human-Machine Bandwidth Gap
Here’s the mismatch laid bare:
| Capability | Silicon (Machine) | Carbon (You) |
|---|---|---|
| Memory | Practically perfect recall | Context evaporates between sessions |
| Processing | Massive parallelism | Serial spotlight of attention |
| Context switching | Microseconds1 | Minutes of cognitive penalty2 |
| Bandwidth | GB/s internal buses | ~40 words/minute3 |
| Consistency | Unfailing (until power loss) | Energy, mood, caffeine cycles |
| Unique strength | Precision + patience | Intuition, creativity, judgment |
We still behave as if the human must contort around the machine. We re-describe projects, paste the same snippets, reconstruct decisions, pay again for intelligence that forgets us instantly. That’s upside down. The machine should be the adaptive party.
Chat UIs were a comforting on-ramp - skeuomorphic leather-bound notebooks for language models. But the paradigm has already shifted. ReAct showed us how to interleave reasoning with tool use4. Toolformer demonstrated models choosing their own tool calls5. MCP gave us a standard protocol for how tools and models communicate6.
An agent isn’t just a chat transcript with a longer context window. It’s continuously alive software with memory, tools, event hooks, and the ability to refine itself. The crucial difference? It remembers everything you would prefer not to reload into working memory.
Think about onboarding a colleague. Week 1, you over-explain everything. Week 4, you reference shared experiences. Week 12, you speak in shorthand. By Week 52, they anticipate your needs. Now imagine hitting Week 1 every single time. That’s most AI today.
With persistent memory, the agent compounds. It internalizes your coding idioms, the architectures you’ve sketched, patterns that succeeded (and the graveyard of those that didn’t). It learns your subtle preferences for naming conventions, error handling styles, even the tempo of how you ask for help. This isn’t a UX garnish - it unlocks qualitatively different kinds of delegation.
Why Local-First Architecture Matters
Cloud AI feels weightless until you examine the friction it normalizes. Your private reasoning streams to someone else’s servers. You pay a metered bill for forgetting. Latency embeds itself in every thought. Terms of service shift beneath you like sand. Export pathways turn rich interaction history into mush.
The blunt truth? You cannot own what you do not physically possess.
Regulation is converging on architecture-as-policy. Keeping intelligence local collapses both attack surface and legal ambiguity. Your data never transits. Latency drops below the threshold where you even notice model spin-up. Costs become a hardware amortization line instead of a variable tax. Extensibility is whatever you can compile, not what an API product manager blessed.
But mostly, it reframes everything. This becomes augmentation you own rather than intelligence you rent.
Yes, I could have prototyped faster in Python. But the minute the agent touches code execution, personal data, and latency-sensitive retrieval, the trade space shifts. Memory safety becomes agent safety - most CVEs trace back to memory corruption7, and policy is finally catching up8. Predictable performance means no surprise GC stalls blowing your 100ms retrieval budget.
Systems-level control unlocked real tricks. Memory-mapped embedding caches hitting in ~0.05ms. Lock-free ingestion. SIMD inner loops. The compiler’s pedantry, annoying at first, turns into long-term leverage as the surface area grows.
What emerges is quiet but radical: you own the augmentation layer. Not a subscription - an asset. It becomes your internal search engine, your memory prosthetic, your pattern spotter, your background executor. And it lives on your laptop.
The Three-Tier Memory Architecture
Here theory finally had to cash the check. I borrowed the scaffolding (multi-store models9, working memory refinements10, complementary learning systems11) but then exploited what silicon can do that biology cannot: lossless, arbitrarily wide recall at predictable latency. The result is a three-tier design:
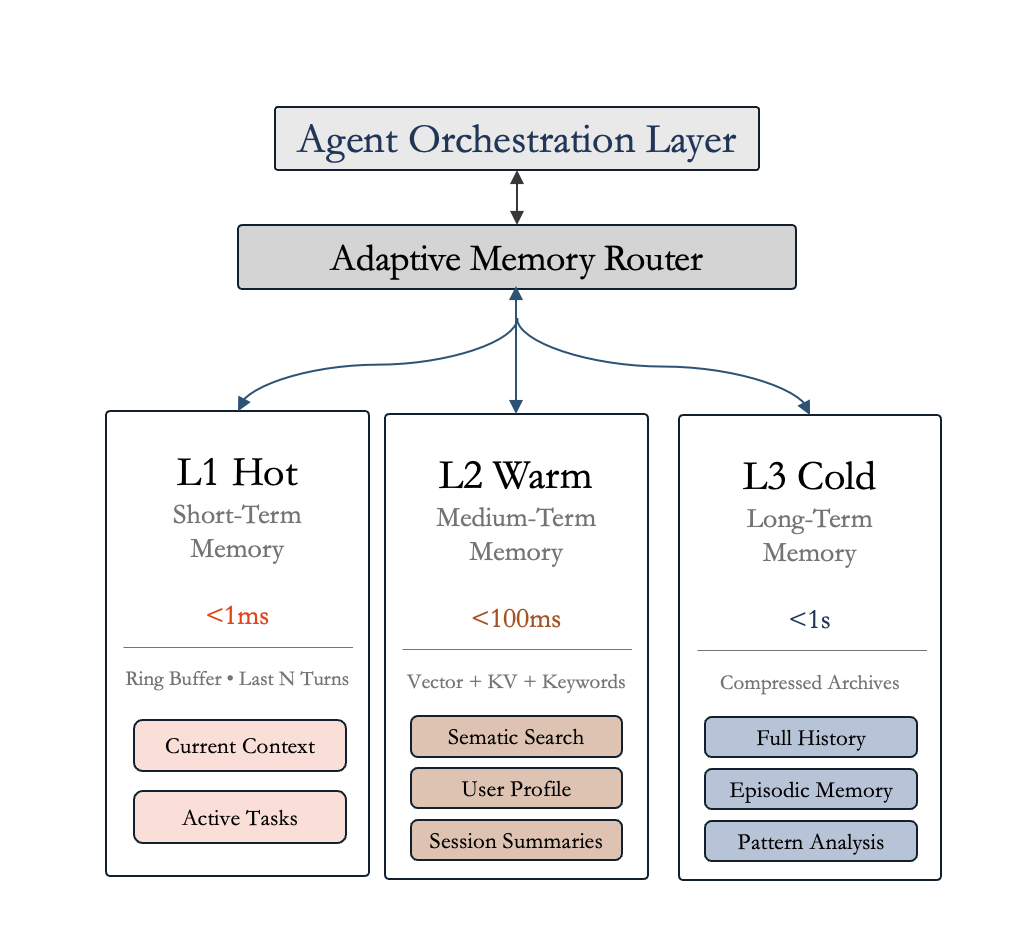
L1 HOT: Working Memory (<1ms) - This is ephemeral, right-now state - the current conversational slice, active task focus, transient scratch variables. A ring buffer holds it all, making lookup effectively free.
L2 WARM: Associative Memory (<100ms) - The accumulation layer where the real magic happens. Dense semantic vectors from BGE-M312 capture meaning. Sparse FTS5/BM25 provides lexical anchoring. ColBERT13-style late-interaction reranking brings precision. A KV substrate stores structured facts and preferences. These scores hybridize through α·cosine + β·BM25 with learned weights14, so both “what did we call that migration script?” and “summarize why we chose SQLite over DuckDB” feel equally snappy.
L3 COLD: Archive (<1s) - Everything lives here. Raw history, compressed episodic bundles, long-tail artifacts you almost never touch - until you do. Retrieval is rare, and when it happens, the result often distills upward into L2, making the system progressively cheaper to consult.
Gluing the tiers together is a lightweight, inspectable router. Most requests never touch the archive; that’s the whole latency story.
fn route_query(q: &Query) -> RouteResult {
// Heuristics cascade hottest → coldest memory tier.
let result = if is_smalltalk(q) {
// L1: cheap working memory only.
query_l1(q)
} else if needs_exact_match(q) {
// Lexical (sparse) + KV merge; dense check guards drift.
sanity_check_dense(query_l2_sparse(q) + query_l2_kv(q))
} else if needs_semantic_search(q) {
// Dense ANN → late interaction rerank → enrich with transient L1 context.
let cand = query_l2_dense_ann(q, TOP_K); // ANN: Approximate Nearest Neighbor search
enrich_from_l1(late_interaction_rerank(cand))
} else if has_low_confidence() || is_long_horizon(q) {
// Confidence fallback / long-horizon: consult archive then promote distilled summary upward.
let raw = tap_l3_archive(q);
promote_to_l2_kv(summarize(raw));
raw
} else {
// Default: treat as semantic to avoid unnecessary archive hops.
let cand = query_l2_dense_ann(q, TOP_K);
enrich_from_l1(late_interaction_rerank(cand))
};
// Telemetry feeds adaptive weighting + promotion heuristics.
log_query_metrics(QueryMetrics { tiers_accessed, latency_ms, confidence_score, provenance });
result
}The payoff: p95 stays sub‑100ms for everyday retrieval because cold storage is opt-in, not habitual. Provenance tagging means you can always see which layer answered you.
From Vision to Implementation
You stop rehydrating context. Conversations become continuations, not reset rituals. The system compounds - it gets specifically better at working with you, not just generally stronger as models advance. Background tasks proceed while you focus elsewhere. “Personalization” stops meaning collaborative filtering and starts meaning something real: an internalized model of how you actually problem-solve.
Vision talk is cheap without measurements, so briefly: embeddings, the memory‑mapped cache, the three‑tier memory stack, the evolution / ingestion pipeline, an MCP server with 11 tools, and 216+ passing tests are already shipping (0.06ms embedding calls, ~0.05ms cache hits, <100ms warm retrieval, 10k fact evolution in ~5ms). In flight: KV cache reuse (target 3–10x speedup15), GAIA benchmarking for external validation16, and multi‑agent shared memory for coordinated tooling.
Capability ceiling (reasoning-grade frontier models), democratized local hardware (Apple Silicon + MLX17), and infrastructure maturity (vLLM18, MCP6, a deep Rust crate ecosystem) finally intersect. The ingredients stopped being speculative; it became an integration problem.
If you’re building along, here’s the path. First, scaffold the tiers - a simple ring buffer for L1, SQLite with FTS5 plus a vector index for L2, and a compressed archive for L3. Then layer in hybrid retrieval, combining semantic embeddings with lexical scoring and late-interaction reranking. Finally, bolt on the router with proper logging, confidence scores, and provenance tracking, so you can see exactly when to promote summaries upward.
Hitting <120ms p95 on a laptop becomes a debugging exercise rather than a moonshot. The code will land as it’s hardened, but the architectural intent is what’s transferable.
I don’t think this is the only viable shape - but it is one that treats carbon and silicon as complementary substrates instead of one mimicking the other. You bring values, prioritization, intuition; the machine brings memory, parallelism, patience. The interface between the two is where the compounding happens.
Coming Next: How I Made Embeddings 130x Faster
Now that you understand why local agents with persistent memory matter, we’ll dive into how to build them.
Next up: “From Process Spawning to PyO3: A 130x Optimization Journey”
How the path from 100ms to sub‑millisecond embeddings mostly involved deleting IPC layers I once thought were harmless.
References
Footnotes
-
Measuring context switching and memory overheads for Linux threads. OS-level context switches in microseconds. ↩
-
Executive Control of Cognitive Processes in Task Switching - American Psychological Association. Cognitive switch costs measured in minutes. ↩
-
Words per minute - Wikipedia. Average adult typing speed ~40 WPM. ↩
-
ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2023). Interleaving reasoning with tool use. ↩
-
Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al., 2023). Self-discovering tool calls. ↩
-
Model Context Protocol (MCP) - Anthropic. Standardized tool and data protocol. ↩ ↩2
-
A proactive approach to more secure code - Microsoft Security Response Center. ~70% of CVEs are memory safety bugs. ↩
-
Future Software Should Be Memory Safe - White House ONCD (2024). ↩
-
The Multi-Store Model (Atkinson & Shiffrin, 1968). Sensory → Short-term → Long-term memory. ↩
-
The episodic buffer: a new component of working memory? (Baddeley, 2000). Modern working memory model. ↩
-
Why there are complementary learning systems (McClelland et al., 1995). Hippocampal-cortical consolidation. ↩
-
BGE M3-Embedding (2024). Multi-lingual, multi-functionality embeddings. ↩
-
ColBERT: Efficient and Effective Passage Search (Khattab & Zaharia, 2020). Late interaction over BERT. ↩
-
Sparse, Dense, and Attentional Representations (Luan et al., 2021). Hybrid retrieval approaches. ↩
-
Automatic Prefix Caching - vLLM and LMCache. KV cache reuse for 3-10x speedup. ↩
-
GAIA: a benchmark for General AI Assistants (2023). Real-assistant benchmark with tool use. ↩
-
MLX: An array framework for Apple silicon. Running LLMs locally on M-series chips. ↩
-
vLLM Metrics Documentation. Time-to-First-Token (TTFT) as primary UX metric. ↩